
文|肖健(花名:昱恒)
蚂蚁集团技术专家
专注于服务发现领域,目前主要从事蚂蚁注册中心 SOFARegistry 设计、研发工作。
本文 9492 字 阅读 24 分钟
PART. 1
前言
1.1 什么是服务发现
在微服务的体系中,多个应用程序之间将以 RPC 方式进行相互通信。这些应用程序的服务实例是动态变化的,我们需要知道这些实例的准确列表,才能让应用程序之间按预期进行 RPC 通信。这就是服务发现在微服务体系中的核心作用。
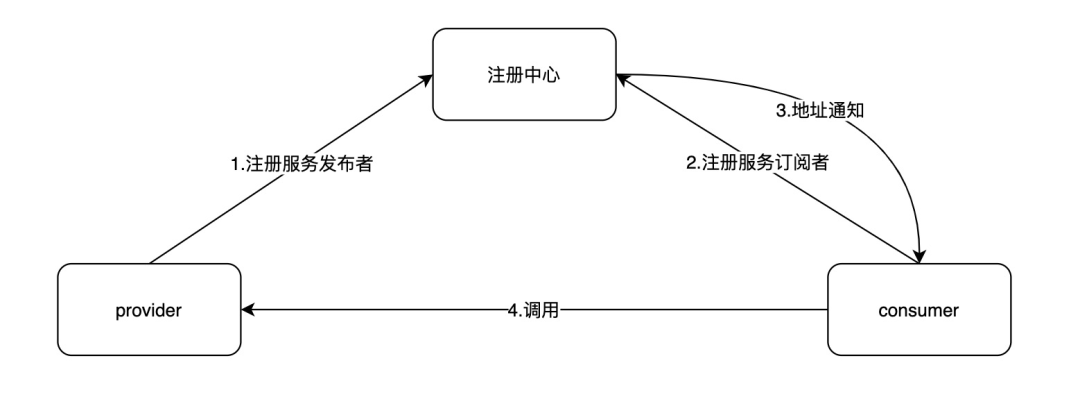
SOFARegistry 是蚂蚁集团在生产大规模使用的服务注册中心,经历了多年大促的考验,支撑蚂蚁庞大的服务集群;具有分布式可水平扩容、容量大、推送延迟低、高可用等特点。
1.2 服务发现的考量
设计和考量一个服务发现系统,可以从下面这些指标展开:
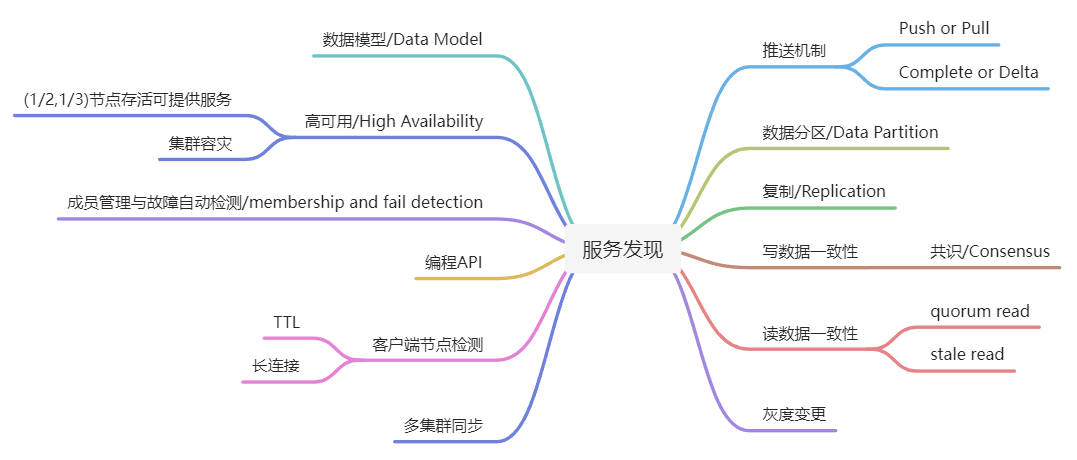
各个指标之间并不是相互独立的。例如对于数据一致性方案的选型也会影响到数据分区、数据复制、集群容灾、多集群同步等方案的决策,也在很大程度上决定这个服务发现系统的整体架构。
这篇文章重点分析了各个服务发现系统的数据一致性方案,以及基于这个方案延伸出来的特性,帮助大家初步了解服务发现系统。
PART. 2
开源产品分析
2.1 为什么需要数据一致性
根据上述描述,数据一致性在服务发现系统中如此重要,甚至会影响到整个服务发现系统的各方面架构考量,那我们到底为什么需要数据一致性呢?
要回答这个问题,让我们从单点故障说起:早期我们使用的服务,以及服务数据存储,它们往往是部署在单节点上的。但是单节点存在单点故障,一旦单节点宕机就整个服务不可用,对业务影响非常大。随后,为了解决单点问题,软件系统引入了数据复制技术,实现多副本。
通过数据复制方案,一方面我们可以提高服务可用性,避免单点故障;另一方面,多副本可以提升读吞吐量、甚至就近部署在业务所在的地理位置,降低访问延迟。
随着多副本的引入,就会涉及到多个副本之间的数据怎样保持一致的问题,于是数据一致性随之而来。
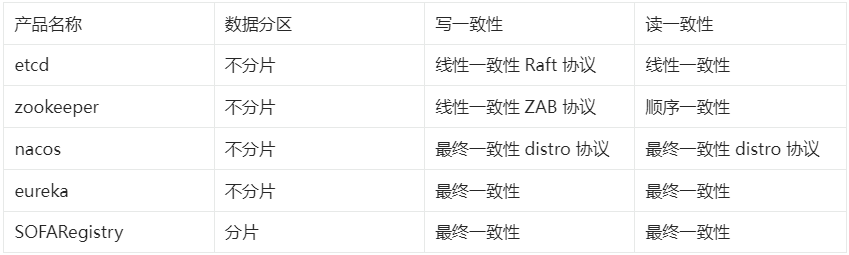
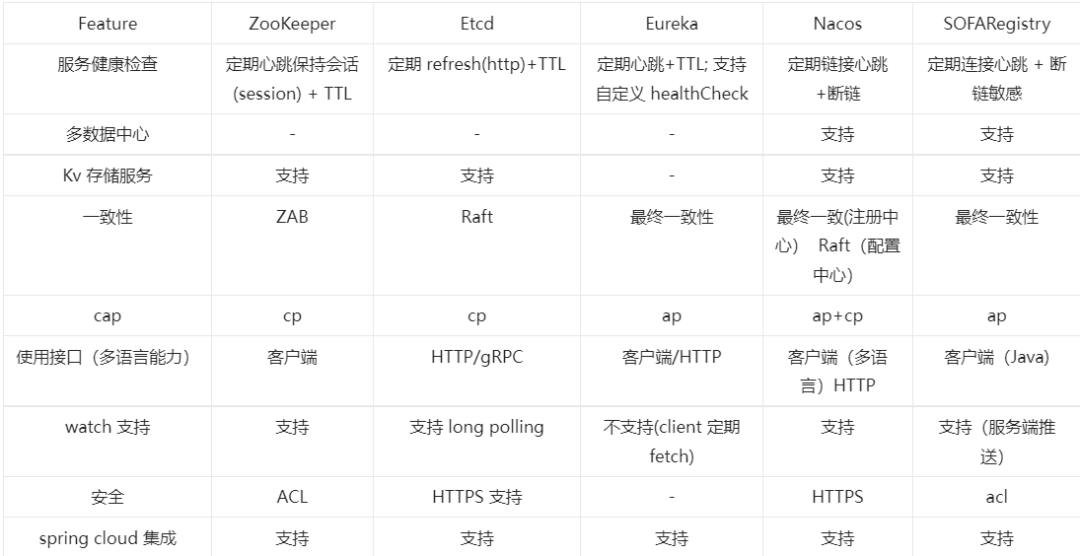
2.2 开源产品分析
对于多个副本之间进行数据同步,一致性关系从强到弱依次是:
●线性一致性(Linearizability consistency)
●顺序一致性(Sequential consistency)
●因果一致性(Causal consistency)
●最终一致性(Eventual consistency)
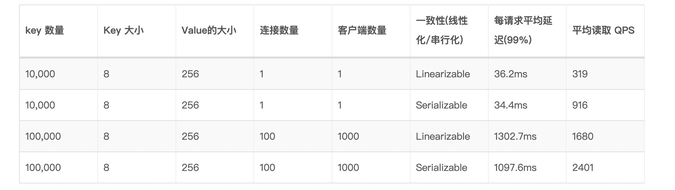
我们对比一下目前开源的比较典型的服务发现产品,在数据一致性上的方案实现:
PART. 3
Etcd 数据一致性
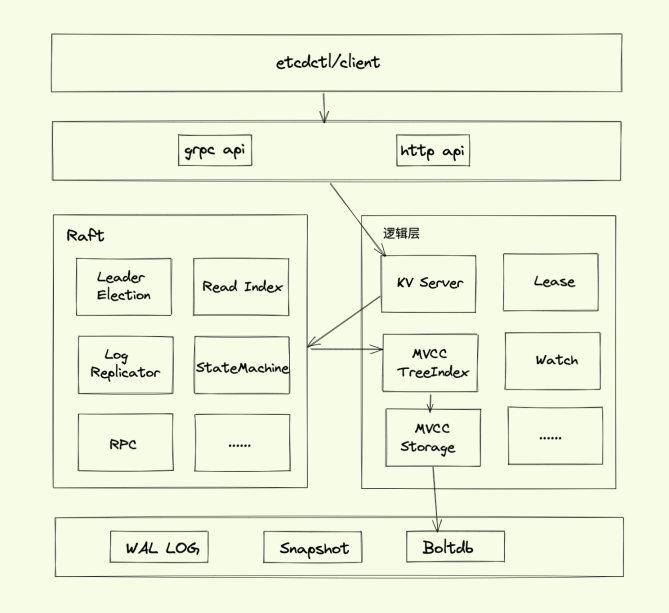
3.1 Etcd 读数据流程
1. Client:Etcdctl 封装了操作 Etcd、KV Server、Cluster、Auth、Lease、Watch 等模块的 API;
2. KV Server:Client 发送 RPC 请求到了 Server 后,KV Server 基于拦截器记录所有请求的执行耗时及错误码、来源 IP 等,也可控制请求是否允许通过;
3. Raft:Etcd 收到读请求后,向 Etcd Raft 模块发起 Read Index 读数据请求,返回最新的 ReadState 结构体数据;
4. MVCC:KV Server 获取到 Read State 数据后,从 MVCC 模块的 Tree Index 读取基于 Key-Version 的唯一标识 Revision;再以 Revision 作为 Key 从 Boltdb 中读取数据。
3.2 Etcd 写数据流程
1. Client:Etcdctl 封装了操作 Etcd、KV Server、Cluster、Auth、Lease、Watch 等模块的 API;
2. KV Server:通过一系列检查之后,然后向 Raft 模块发起(Propose)一个提案(Proposal),提案内容为存储的 value;
3. Raft:
向 Raft 模块发起提案后,KV Server 模块会等待此 put 请求;如果一个请求超时未返回结果,会出现的 EtcdServer:request timed out 错误。
Raft 模块收到提案后,如果当前节点是 Follower,它会转发给 Leader,只有 Leader 才能处理写请求。Leader 收到提案后,通过 Raft 模块将 put 提案消息广播给集群各个节点,同时需要把集群 Leader 任期号、投票信息、已提交索引、提案内容持久化到一个 WAL(Write Ahead Log)日志文件中,用于保证集群的一致性、可恢复性。
4. Raft 模块提交 Proposal 完成后,向 MVCC 模块提交写数据。
3.3 Raft 功能分解
共识算法的祖师爷是 Paxos, 但是由于它过于复杂、难于理解,工程实践上也较难落地,导致在工程界落地较慢。
Standford 大学的 Diego 提出的 Raft 算法正是为了可理解性、易实现而诞生的,它通过问题分解,将复杂的共识问题拆分成三个子问题,分别是:
●Leader 选举:Leader 故障后集群能快速选出新 Leader;
●日志复制:集群只有 Leader 能写入日志, Leader 负责复制日志到 Follower 节点,并强制 Follower 节点与自己保持相同;
●安全性:一个任期内集群只能产生一个 Leader、已提交的日志条目在发生 Leader 选举时,一定会存在更高任期的新 Leader 日志中、各个节点的状态机应用的任意位置的日志条目内容应一样等。
下面以实际场景为案例,分别深入讨论这三个子问题,看看 Raft 是如何解决这三个问题,以及在 Etcd 中的应用实现。
关于 Raft 的 Leader 选举与日志复制,可以从 http://www.kailing.pub/raft/index.html 动画中进一步了解。
3.4 Etcd 读写一致性
3.4.1 线性一致性写 (Linearizable Write)
所有的 Read/Write 都会来到 Leader,Write 会有 Oplog Leader 被序列化,依次顺序往后 commit,并 Apply 然后在返回,那么一旦一个 Write 被 committed,那么其前面的 Write 的 Oplog 一定就被 committed 了。所有的 Write 都是有严格的顺序的,一旦被 committed 就可见了,所以 Raft 是线性一致性写。
3.4.2 线性一致性读 (Linearizable Read)
Etcd 默认的读数据流程是 Linearizability Read,那么怎么样才能读取到 Leader 已经完成提交的数据呢?
读请求走一遍 Raft 协议
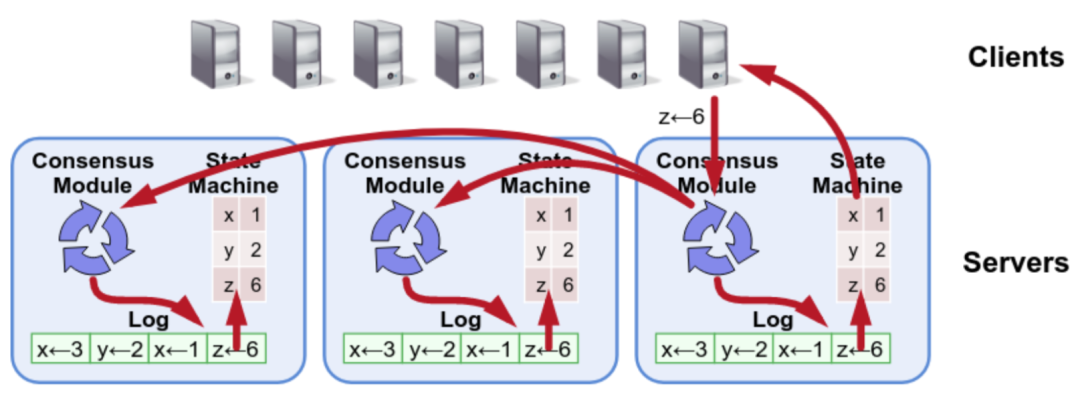
每个 Read 都生成一个对应的 Oplog,和 Write 一样,都会走一遍一致性协议的流程,会在此 Read Oplog 被 Apply 的时候读,那么这个 Read Oplog 之前的 Write Oplog 肯定也被 Applied 了,那么一定能够被读取到,读到的也一定是最新的。
●有什么问题?
不仅有日志写盘开销,还有日志复制的 RPC 开销,在读比重较大的系统中是无法接受的;
还多了一堆的 Raft '读日志'。
Read Index
●这是 Raft 论文中提到过的一种优化方案,具体来说:
Leader 将当前自己 Log 的 Commit Index 记录到一个 local 变量 Read Index 里面;
向其它节点发起一次 Heartbeat,如果大多数节点返回了对应的 Heartbeat Response,那么 Leader 就能够确定现在自己仍然是 Leader;
Leader 等待自己的状态机执行,直到 Apply Index 超过了 Read Index,这样就能够安全的提供 Linearizable Read 了;
Leader 执行 Read 请求,将结果返回给 Client。
●Read Index 小结:
相比较于走 Raft Log 的方式,Read Index 读省去了磁盘的开销,能大幅度提升吞吐,结合 JRaft 的 batch + pipeline ACK + 全异步机制,三副本的情况下 Leader 读的吞吐接近于 RPC 的上限;
延迟取决于多数派中最慢的一个 Heartbeat Response。
Lease Read
●Lease Read 与 Read Index 类似,但更进一步,不仅省去了 Log,还省去了网络交互;它可以大幅提升读的吞吐,也能显著降低延时;
●基本的思路是 Leader 取一个比 election timeout(1s)小的租期(最好小一个数量级,100ms), 在租约期内不会发生选举,这就确保了 Leader 不会变,所以可以跳过 Read Index 的第二步,也就降低了延时。
3.4.3 串行性读(Serializable Read)
直接读状态机数据返回、无需通过 Raft 协议与集群进行交互的模式,在 Etcd 里叫做串行 (Serializable) 读,可以通过 WithSerializable() 进行设置,它具有低延时、高吞吐量的特点,适合对数据一致性要求不高的场景。
PART. 4
Eureka 数据一致性
4.1 Eureka 数据读写流程
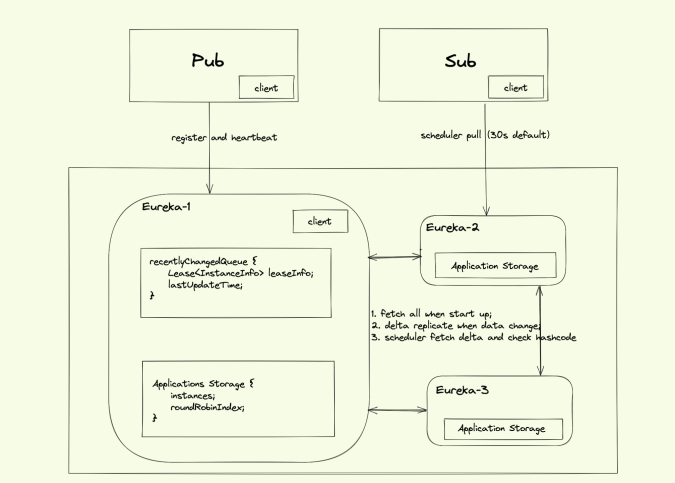
●Eureka 节点完全对等部署,每台 Server 保存全量的数据:
●Sub 会定时(Eureka.client.registry-fetch-interval-seconds 定义,默认值为 30s)向注册中心获取数据,更新本地缓存;
●服务实例会通过心跳 (Eureka.Instance.lease-renewal-interval-in-seconds 定义心跳的频率,默认值为 30s) 续约的方式向 Eureka Server 定时更新自己的状态。Eureka Server 收到心跳后,会通知集群里的其它 Eureka Server 更新此实例的状态。Service Provider/Service Consumer 也会定时更新缓存的实例信息。
●服务的下线有两种情况:
在 Service Provider 服务 shutdown 的时候,主动通知 Eureka Server 把自己剔除,从而避免客户端调用已经下线的服务;
Eureka Server 会定时(间隔值是 Eureka.server.eviction-interval-timer-in-ms,默认值为 0,默认情况不删除实例)进行检查,如果发现实例在在一定时间(此值由 Eureka.Instance.lease-expiration-duration-in-seconds 定义,默认值为 90s)内没有收到心跳,则会注销此实例。
4.2 启动全量拉取
private boolean fetchRegistry() {// If the delta is disabled or if it is the first time,get all applicationsif (serverConfig.shouldDisableDeltaForRemoteRegions()|| (getApplications() == null)||(getApplications().getRegisteredApplications().size() == 0)) {// 全量获取logger.info("Disable delta property : {}",serverConfig.shouldDisableDeltaForRemoteRegions());logger.info("Application is null : {}",getApplications() == null);logger.info("Registered Applications size is zero :{}", getApplications().getRegisteredApplications().isEmpty());success = storeFullRegistry();} else {//增量获取success = fetchAndStoreDelta();}return success;
}
1. Eureka-Server 的复制算法是依赖增量复制+全量复制实现的。区别于 ZooKeeper,这里没有 Leader 的概念,所有的结点都是平等的,因此数据并不保证一致性。
2. 启动时调用 storeFullRegistry,选取 1 台 Eureke-Server 进行一次全量拉取,使用 EurekaHttpClient.getApplications();url="/apps" ;
3. Server 端获取本地 Cache 中的数据进行返回。
4.3 数据变更增量复制
4.3.1 Client 发起复制
1. 此处的 Client 指的是 Eureka-1,当 Eureka-1 收到客户端的服务注册(Registers)、服务更新(Renewals)、服务取消(Cancels)、服务超时(Expirations)和服务状态变更(Status Changes)后,刷新本地注册信息;
2. 遍历所有的节点(会排除自己),将消息转发到其它节点;为了实现数据同步(Eureka 保证的 AP 特性),每个节点需要维护一个节点列表,这个节点列表就是 PeerEurekaNodes,她负责管理所有的 PeerEurekaNodes;
3. 转发请求时,在 HTTP Header 中携带 x-netflix-discovery-replication : true 的标识,则处理请求的机器不会再将请求继续转发,避免死循环。
/*** Replicates all instance changes to peer Eureka nodesexcept for* replication traffic to this node.**/
private void replicateInstanceActionsToPeers(Action action,String appName,String id,InstanceInfo info, InstanceStatus newStatus,PeerEurekaNodenode) {switch (action) {case Cancel:node.cancel(appName, id);break;case Heartbeat:InstanceStatus overriddenStatus =overriddenInstanceStatusMap.get(id);infoFromRegistry =getInstanceByAppAndId(appName, id, false);node.heartbeat(appName, id, infoFromRegistry,overriddenStatus, false);break;case Register:node.register(info);break;case StatusUpdate:infoFromRegistry =getInstanceByAppAndId(appName, id, false);node.statusUpdate(appName, id, newStatus,infoFromRegistry);break;case DeleteStatusOverride:infoFromRegistry =getInstanceByAppAndId(appName, id, false);node.deleteStatusOverride(appName, id,infoFromRegistry);break;}
}@Override
public EurekaHttpResponse
4.3.2 Server 处理增量复制
1. Server 收到数据变更请求后,根据 lastDirtyTimestamp 处理数据版本冲突,lastDirtyTimestamp 是注册中心里面服务实例(Instance)的一个属性,表示此服务实例最近一次变更时间;
2. Eureka Server A 把数据发送给 Eureka Server B,数据冲突有 2 种情况:
A 的数据比 B 的新,B 返回 404,A 重新把这个应用实例注册到 B;
A 的数据比 B 的旧,B 返回 409,要求 A 同步 B 的数据。
public void register(InstanceInfo registrant, int leaseDurtion, boolean isReplication) {// .... 获取 instance 实例对象Lease
}
4.4 Apps 定时增量同步与校验
4.4.1 Client
在 Eureka Server 启动完成初次全量同步后,考虑从增量数据复制会有处理失败的情况,所以需要有一个定时任务每隔 30s 进行增量数据同步与校验:
@Override
public EurekaHttpResponse
}private boolean fetchAndStoreDelta() throws Throwable {long currGeneration = fetchRegistryGeneration.get();Applications delta = fetchRemoteRegistry(true);String recOncileHashCode= "";//加锁进行差量更新if (fetchRegistryUpdateLock.tryLock()) {try {updateDelta(delta);reconcileHashCode =getApplications().getReconcileHashCode();} finally {fetchRegistryUpdateLock.unlock();}} else {logger.warn("Cannot acquire update lock, aborting udateDelta operation of fetchAndStoreDelta");}// There is a diff in number of instances for somereasonif (!reconcileHashCode.equals(delta.getAppsHashCode())){deltaMismatches++;return reconcileAndLogDifference(delta,reconcileHashCode);} else {deltaSuccesses++;}return delta != null;
}
1. 增量数据同步成功后加锁,进行 add、modify、 delete 等操作,url="apps/delta";
2. 使用 updateDelta 更新数据后,使用 reconcileHashCode(根据 Client 和 Server 的全量 Applications 计算获得)校验是否增量更新成功,reconcileHashCode 格式:UP_count1_DOWN_count2_STARTING_count3;
3. 如果校验的 reconcileHashCode 不一致,再发起一次全量同步动作;
4.4.2 Server
private ConcurrentLinkedQueue
@Deprecated
public Applications getApplicationDeltas() {//从ecentlyChangedQueue获取增量同步的数据Iterator
1. 从 recentlyChangedQueue 队列中获取增量数据,根据方法的注释,recentlyChangedQueue 中存放的是 getRetentionTimeInMSInDeltaQueue 时间内(默认 180s)的 Client 注册信息;
2. Client 发起 Delta 增量同步时,前后两次请求可能获取到相同的 Delta Apps 信息,Client 需要兼容这种情况;
3. Eureka Server 收到 Register、Cancel、StatusUp、Expirations 等操作时,会更新 recentlyChangedQueue 中的信息;
4. 设置定时任务(30s 运行一次)清理队列中的过期数据(180s)。
4.5 点评
1. Client 30s 向服务端获取一次数据,Service 变化生效时间较长;
2. 使用 recentlyChangedQueue 保存 180s 数据变更的方式进行增量同步,如果数据量大队列容易爆炸;
3. 如果 reconcileHashCode 在增量同步的时候计算不一致,发起全量同步,如果全量同步的次数太多,容易有性能瓶颈;
4. reconcileHashCode 格式:UP_count1_DOWN_count2_STARTING_count3,只是确保 UP/DOWN 数量相等,无法保证数据是最终一致性。
PART. 5
Nacos 数据一致性
5.1 Nacos 数据读写流程
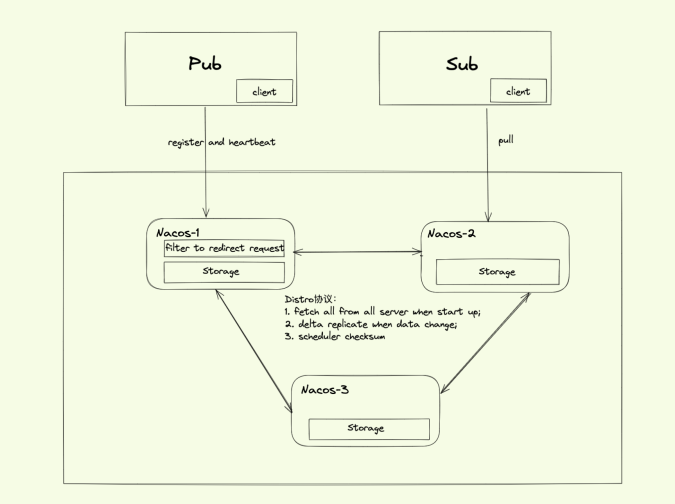
1. Nacos 使用的是单节点全量存储数据,Client 与单个 Nacos 节点进行服务的发布和订阅;
2. 每个 Server 中有一个请求处理的前置 Filter,根据 Server 列表的 Hash 分片,计算 Pub 数据归属于哪台 Nacos-Server,然后进行请求转发;
3. Nacos-1 中调用本地的 Register 方法,将服务信息存储到本地内存的服务注册列表,然后给 Client 返回成功;
4. Nacos-1 根据 Distro 协议,将 Pub Register 请求同步给全集群的 Nacos Server;
5. Sub Client 连接到 Nacos-3 进行服务数据订阅,Nacos-3 将本地数据进行返回。
5.2 启动全量拉取
1. 新加入的 Distro 节点会进行全量数据拉取,具体操作是轮询所有的 Distro 节点,通过向其它的机器发送请求拉取全量数据;
2. Nacos v1 基于 HTTP 协议进行通信,v2 基于 gRPC 协议进行通信;
3. 启动期间需要向全量的 Distro 机器都发起全量拉取:
对于新的机器,从处理读请求的角度看,可以只拉取 1 台 Distro 的机器数据,即使获取的部分数据是比较旧的,也只是与拉取的 Target Server 提供了相同的数据服务;
从处理写请求的角度看,只有从全量的机器拉取,才能确保本机器负责的 Hash 分片的数据最新,所以需要向所有的 Distro Server 做数据同步,确保本机负责的 Hash 分片的数据最新;
4. 在全量拉取操作完成之后,Nacos 的每台机器上都维护了当前的所有注册上来的非持久化实例数据,开始提供服务。
5.3 数据变更增量复制
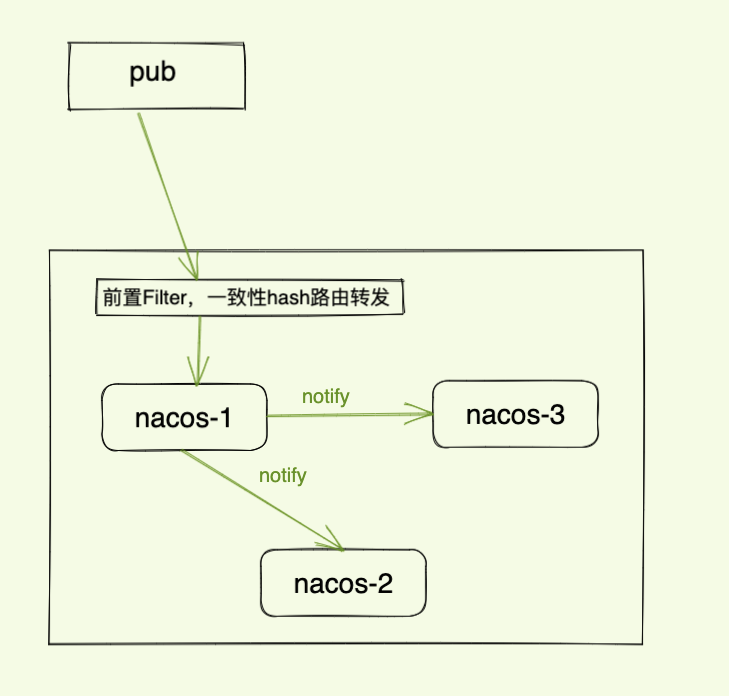
●对于 add、change、delete,在 Nacos-1 执行后,将数据变更与 action 广播到全集群的 Distro 服务器;
有了上述两个机制之后,也不能完全确保 Distro 服务器之间的数据完全是相同的,例如存在 Notify 失败等场景。因此还需要有一个定时校验机制,比对全集群的 Server 之间的数据一致性,并进行修复。
5.4 v1 版本节点数据 Verify
●Nacos-1 每隔 5s 执行一次定时任务,计算本节点数据的 digest 摘要;
●Verify 校验时,将本地的所有 Service,根据 Hash 规则匹配本节点负责的 Service,并计算对应的 CheckSum,然后组装成请求参数:Map
●CheckSum 的计算规则如下:
public synchronized void recalculateChecksum() {List
}
●Nacos-2 Server 端收到 Verify 请求后,将数据分成 3 种场景:不需要处理的、需要更新的、需要删除的;
对于需要删除的 Service 数据,直接在内存中删除;
对于需要更新的 Service,调用 Nacos-1 进行 Server 的全量数据获取,然后更新本地的数据。
// 对于有差异的 service 进行全量数据同步
@Override
public DistroData getData(DistroKey key, String targetServer) {try {List
}
示意图:
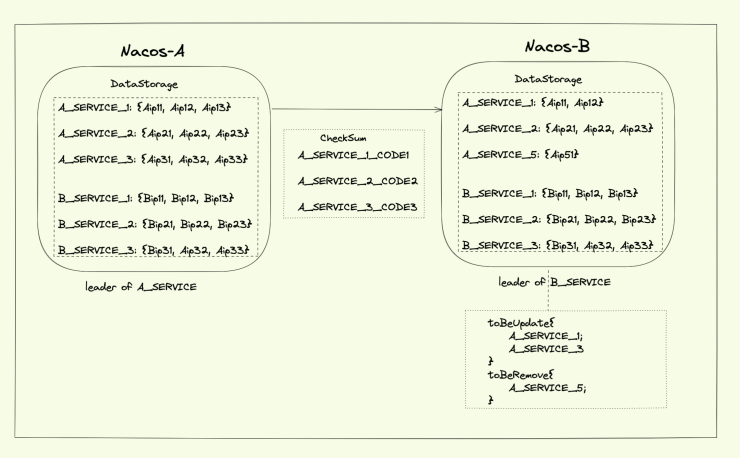
●假设现在有 2 个节点,Nacos-A 是 A_SERVICE_XXX 服务的 Leader 节点,Nacos-B 是 B_SERVICE_XXX 服务的 Leader 节点;
●Nacos-A 发送 CheckSum 请求时,将自己作为 Leader 的 A_SERVICE_XXX 分别计算 md5code;
●md5code 生成规则:ip.getIp() + ":" + ip.getPort() + "_" + ip.getWeight() + "_" + ip.isHealthy() + "_" + ip
.getClusterName();
●在 Nacos-B 中计算出有差异的 A_SERVICE_XXX,对于需要 Update 的从 Nacos-A 中进行全量数据拉取;对于需要 Remove 的从内存中删除。
5.5 v2 版本 Verify
●区别于 v1 版本的实现,v2 中以 ClientId 维度进行 CheckSum;
●Nacos-1 对于本节点的所有 ClientId,每个 ClientId都包装成一个 Task 任务,使用 gRPC 发送给所有的 Distro 节点;
@Override
public List
}
●每个 ClientId 发送的校验 Version=1,Version 作为保留的扩展特性;
●接收 Verify 请求的节点从请求参数中获取 ClientId,并检查自身是否有这个 Client,若此 Client 存在,则更新 Client 下的所有 Instance、以及 Client 自身的最新活跃时间为当前时间。
5.6 小结
1. V1 Distro 最终数据一致性:
计算每个 Service 的 CheckSum 时,使用的是 ip.getIp() + ":" + ip.getPort() + "_" + ip.getWeight() + "_" + ip.isHealthy() + "_" + ip.getClusterName() 进行 CheckSum 计算;
对于需要更新的数据,向原节点全量拉取 Service 的数据;可以考虑优化成差量拉取。
2. V2 Distro 最终一致性:每个节点以 ClientId 为维度进行集群广播,以 ClientId,Version=0 进行数据校验。
PART. 6
SOFARegistry
6.1 Registry 数据读写
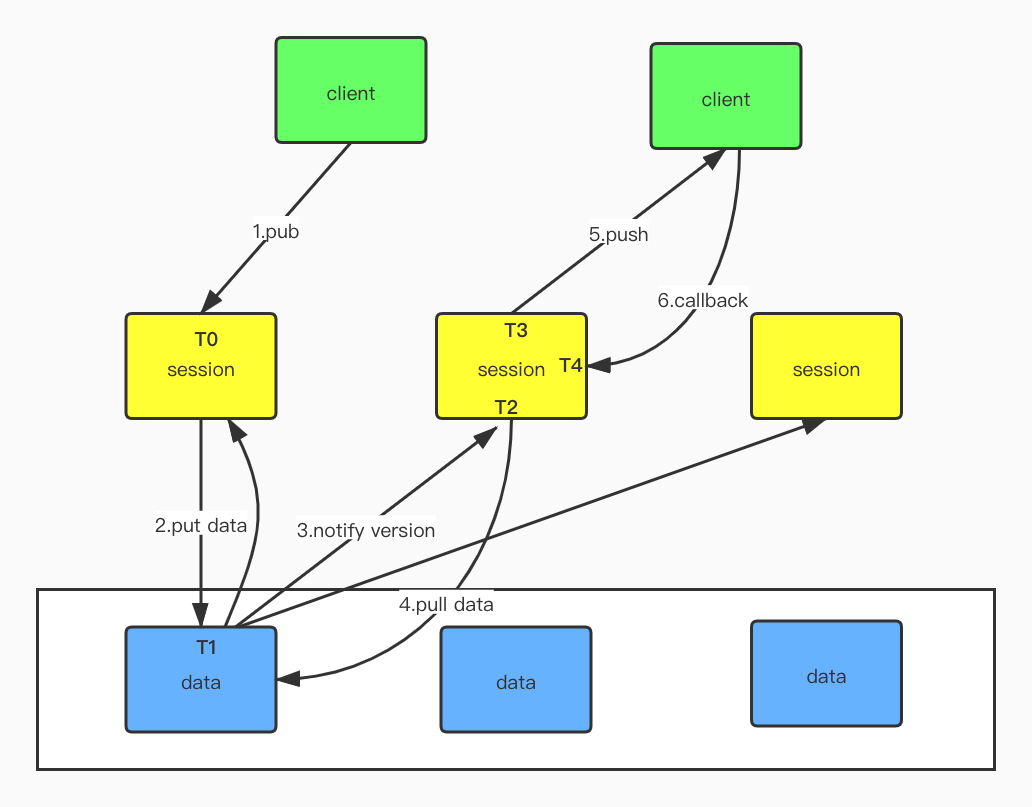
1. Client 发起服务注册数据 Publisher 给 SessionServer,SessionServer 接收成功;
2. SessionServer 接收到 Publisher 数据后,首先写入内存 (Client 发送过来的 Publisher 数据,SessionServer 都会存储到内存,用于后续可以跟 DataServer 做定期检查),然后将 Publisher 数据发送给 DataServer,DataServer收到 Session 的 Pub 之后,修改 Datum 的版本号;
3. DataServer 先对 Notify 的请求做 merge 操作(等待 1000ms),然后将数据的变更事件通知给所有 SessionServer (事件内容是 ID 和版本号信息和版本号信息:
4. SessionServer 接收到变更事件通知后,对比 SessionServer 内存中存储的 DataInfoId 的 Version,发现比 DataServer 发过来的小,所以主动向 DataServer 获取 DataInfoId 的数据,即获取具体的 Publisher 列表数据,获取数据成功后,创建 pushTask;
5. SessionServer 检测 pushTask 是否达到执行时间(T2+500MS),对于达到执行时间的 pushTask,从队列中取出 Task,开始进行推送;
6. SessionServer 将数据推送给相应的 Client、Client Callback、SeesionServer 收到 ACK。
6.2 v6 秒级数据一致性
详见 https://www.sofastack.tech/projects/sofa-registry/code-analyze/code-analyze-data-synchronization/ 本文不再重复描述。
6.3 多机房数据一致性
在 6.2 的同机房 Data-Leader 与 Data-Follower 数据同步的方案下,可以将这个方案进一步扩展到多机房之间的数据同步:
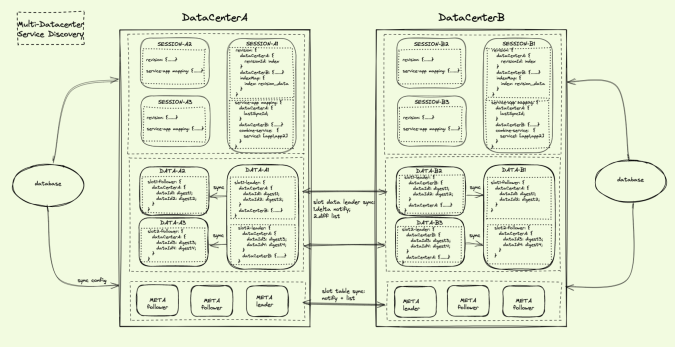
Meta 跨机房同步 SlotTable:
1. 数据:本机房 SlotTable 数据;
2. 通信:全量轮询;
3. DataCenterB Meta Leader 定时拉取到 DataCenterA 集群的 SlotTable 数据更新后,保存到本地 Meta Leader 内存中,然后通知给 DataCenterB 集群的 Data 和 Session。
Data 跨机房同步 SlotData:
1. 数据:每台 Data 同步自身 Slot Leader 的数据;
2. 通信:增量通知+全量 DataInfoId 定时比对拉取;
3. Data-A1 和 Data-B2 从 Meta 获取到完整的 SlotTable 数据后,可以解析到自己是 SlotId=1 的 Leader 节点,需要进行数据同步;
4. 当 Data-B2 中收到本机房 Session 的 Pub、ubPub、Client_off 请求后,完成本机房 Datum 数据处理;然后将 Datum.Version 通知给本机房 Session,同时将具体的 Pub、ubPub、Client_off 请求发送给 Data-A1;
5. Data-A1定时将 SlotId=1 的摘要数据发送给 Data-B2,将 SlotId=2 的摘要数据发送给 Data-B3,返回有差异的 DataInfoId 列表;再将差异 DataInfoId 进行性细的 Pub 摘要对比,确保数据最终一致;
6. Data-A1 将变化的 DataInfoId 以及 Datum Version 通知给本集群所有的 Session,将 DataCenterB 的数据变化推送给 DataCenterA 的所有 Client。
PART. 7
总结
最后我们对 SOFARegistry 和其它开源产品进行总结对比:
了解更多...
SOFARegistry Star 一下✨:
https://github.com/sofastack/sofa-registry/
本周推荐阅读

SOFARegistry | 大规模集群优化实践

SOFARegistry 源码|数据同步模块解析
SOFARegistry 源码|数据分片之核心-路由表 SlotTable 剖析

SOFAServerless 体系助力业务极速研发









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
